Prediction
The Prediction structural pattern is a derivative of the Fault Diagnosis architectural pattern and the Fault Treatment strategy pattern in the original resilience design pattern specification (Fig. 32) [B24]. It predicts future faults that have not been activated based on the idea that such future faults have detectable precursors. The following describes the Pattern and its application in the System Scope and in the Service Scope of the INTERSECT federated ecosystem for instrument science. Note that the Pattern description uses the terms system, subsystem, and service in an abstract way, while the System Scope and the Service Scope map those terms to the INTERSECT federated ecosystem.
Pattern
- Problem
Not anticipating the presence, root cause, and impact of a defect or anomaly in the system causes lack of corrective action at design or run time and may eventually result in an error or failure.
- Context
The pattern applies to a system that has the following characteristics:
The system has well-defined parameters that enable a monitoring system to discover the presence of a defect or anomaly in the behavior of the monitored system.
The interaction between the monitored and monitoring systems is bounded in terms of time.
The monitoring system has the capability to store historical data about the behavior of the monitored system to analyze it for defect or anomaly occurrences.
- Forces
The interactions between the monitoring and monitored systems may interfere with the operation of the monitored system, specifically its performance.
While the frequency and duration of these interactions must be minimized to reduce the monitoring overhead, the interactions must be able to detect/infer a defect or anomaly in the monitored system.
The monitoring system’s data gathering and defect/anomaly detection/inference must be in time to prevent the activation of an error and a subsequent failure.
The diagnostic resolution, i.e., the degree of accuracy of the fault diagnosis, must be high to be effective.
- Solution
The pattern enables the discovery and treatment of a defect or anomaly in the system, which has the potential to activate an error and potentially a subsequent failure. It supports methods that attempt to recognize the potential of a future defect or anomaly within a monitored system. It prevents its activation or enables its containment and mitigation by notifying the monitored system about a future fault with location and type information, such that the anomaly or defect is removed before or after it results in an error or a failure.
The solution requires a monitoring system, which may be a subsystem of the monitored system or an external independent system, to observe key parameters of the monitored system and to notify the monitored system when these parameters deviate. The pattern identifies anomalous behavior that indicates the potential for a future fault, which may result in an error or failure in the system. The monitoring system may approach the problem using two strategies:
- Statistical Method
The monitoring system discovers probabilistic characteristics of a potential fault in the system using statistical inference techniques that examine correlations with previous events.
- Rule-based Method
The monitoring system builds rules of association to capture the causal correlations between system parameter values and faults.
The monitoring system contains the following components to predict faults in the monitored system:
- Filter/Preprocessor
This component removes incomplete monitoring data and duplicates and produces a consistent monitoring data format for analysis.
- Regression
This component analyzes the monitoring parameter values and establishes relationships between them.
- Knowledge Base
This storage component maintains the rules or statistical properties and models to be used for online prediction of faults using real-time monitoring data captured from the monitored system.
The components of this pattern are illustrated in Fig. 36.
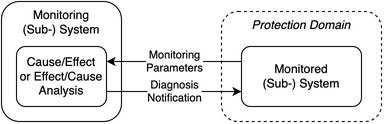
Fig. 36 Prediction pattern components
- Capability
The pattern provides fault anticipation in the monitored system at design or run time, before it eventually results in an error or failure or after activation, by identifying deviations in monitored parameters. This pattern enables containment and mitigation of a future, imminent, or present error or failure in the monitored system through prediction and by notifying the monitored system about a future fault with location and type information. A system using the pattern is able to predict faults and take corrective action at design and run time. This pattern provides fault prediction/detection in the monitored system at design or run time, before it eventually results in an error or failure or after activation, by identifying deviations in monitored parameters and performing regression and statistical/rule-based modeling.
The pattern enables containment and mitigation of a future, imminent or present error or failure in the monitored system through detection and by notifying the monitored system about a fault with location and type information based on regression and statistical/rule-based modeling. The flowchart of the pattern is shown in Fig. 37, the state diagram in Fig. 38, and its parameters in Table 5.
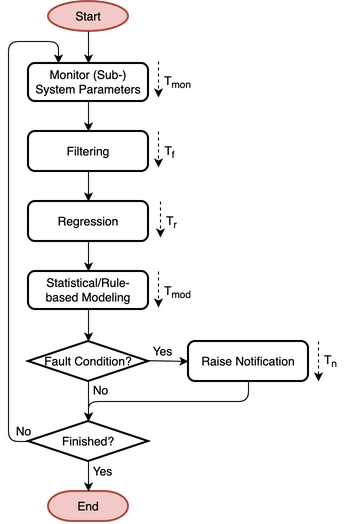
Fig. 37 Flowchart
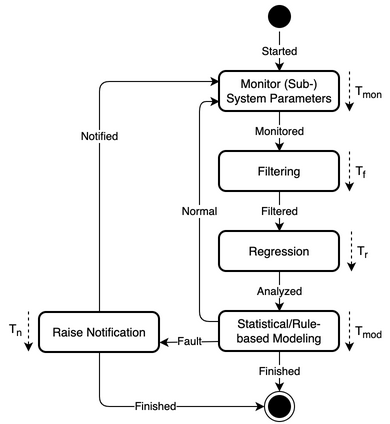
Fig. 38 State diagram
Table 5 Prediction pattern parameters Parameter
Definition
\(T_{mon}\)
Time to monitor (sub-) system parameters, including wait and probe times
\(T_{f}\)
Time to perform the filtering
\(T_{r}\)
Time to perform the regression
\(T_{mod}\)
Time to perform the statistical/rule-based modeling
\(T_{n}\)
Time to raise notification
- Protection Domain
The protection domain extends to the monitored system.
- Resulting Context:
The discovery and treatment of a defect or anomaly in the system that has the potential to activate are enabled, which can be used to prevent, contain, and mitigate an error or a failure in the system. The pattern requires identifying system parameters that indicate the potential for a fault. The overall system design must include a monitoring system, which introduces design complexity. When the monitoring system is extrinsic to the monitored system, the design effort may be simplified, but the interfaces between the monitoring and monitored systems must be well-defined. When the monitoring system is intrinsic to the design of the monitored system, design complexity increases due to the need to interface the monitoring and monitored subsystems.
A trade-off exists between interference with the operation of the monitored system caused by the frequency and duration of the interactions between the monitoring and monitored systems, and the ability to detect/infer a defect or anomaly in the monitored system. A high performing solution reduces the interference, while maintaining a reasonable ability to detect/infer a defect or anomaly.
The pattern may be used in conjunction with other patterns that provide containment and mitigation and require or can make use of fault prediction/detection. It detects the presence of a defect or anomaly and reports it, but does act to remedy the future fault. Based on the monitored system design and accessibility of the parameters selected for observation, the diagnosis may not be very precise and may sometimes give no indication. An efficient implementation performs regression and statistical/rule-based modeling with a reasonable degree of precision and recall.
- Performance
In the case when the monitoring system is not a part of the monitored system, the monitoring system doesn’t impact the task’s total execution time \(T_{E}\). The error/failure-free performance \(T_{f=0}\) is \(T_{E}\).
When the monitoring system is a part of the monitored system, then it does impact the task’s’ total execution time. The error/failure-free performance \(T_{f=0}\) of the pattern is defined by the task’s total execution time \(T_{E}\), the time to monitor sub-system parameters \(T_{mon}\), the time to perform the filtering \(T_{f}\), the time to perform the regression \(T_{r}\), and the time to perform the statistical/rule-based modeling \(T_{mod}\) with the total number of input-execute-output cycles \(P\). Assuming constant times for \(T_{mon}\), \(T_{f}\), \(T_{r}\), and \(T_{mod}\), \(T_{f=0}\) can be defined as:
\[\begin{aligned} T_{f=0} = T_{E} + P(T_{mon} + T_{f} + T_{r} + T_{mod}) \end{aligned}\]The performance under errors/failures \(T_{f!=0}\) is defined by the error/failure-free performance \(T_{f=0}\), plus the time \(T_{n}\) to raise \(N\) notifications with type and location. Assuming constant time for \(T_{n}\), \(T_{f!=0}\) can be defined as:
\[\begin{aligned} T_{f!=0} = T_{f=0} + N T_{n} \end{aligned}\]- Reliability
As the pattern only detects errors or failures, the reliability remains the same with an assumed constant probabilistic error/failure rate \(\lambda\) (or its corresponding inverse, the mean-time to interrupt (MTTI) \(M\)).
\[\begin{aligned} R(t) = e^{-\lambda T_{f!=0}} = e^{-T_{f!=0}/M} \end{aligned}\]- Availability
The availability of the pattern can be calculated using the task’s total execution time without the pattern \(T_{E}\) and performance under errors/failures \(T_{f!=0}\). \(T_{E}\) is the planned uptime (PU) \(t_{pu}\). \(T_{f!=0}\) is the planned uptime (PU) \(t_{pu}\), the scheduled downtime (SD) \(t_{sd}\), and the unscheduled downtime (UD) \(t_{ud}\).
\[\begin{aligned} A = \frac{T_{E}}{T_{f!=0}} = \frac{t_{pu}}{t_{pu}+t_{ud}+t_{sd}} \end{aligned}\]
- Examples
In proactive fault tolerance, an observe-orient-decide-act (OODA) loop control is employed that utilizes monitoring tools for collecting sensor data (e.g., temperature, fan speeds, voltages, computational load, memory and storage usage, etc.). It leverages the warning thresholds of these sensors as early fault indicators to migrate computation away from compute nodes that are about to fail [B46]. The mitigation may use process-level [B47] or virtual machine (VM) level [B48] migration.
Monitoring tools collecting event data (e.g., anomalous, error and failure events, debug messages, etc.) are used in conjunction with tools for temporal and spatial filtering to identify event correlations and to predict failures [B49].
Probabilistic networks are utilized for establishing correlations between event collected with monitoring tools to predict failures [B50].
- Rationale
The pattern enables a system to discover and treat a defect or anomaly in the system that has the potential to activate and become an error or failure. It relies on a monitoring system to observe the monitored system, identifying deviations in monitored parameters. A discovered defect or anomaly is treated by raising a notification about a future fault with location and type information, permitting the monitored system to provide containment and mitigation. A key benefit of this pattern is prediction of faults in the system, before they are activated and result in errors or failures. Preventive actions taken upon such discovery avoid the need for expensive error/failure recovery, compensation, or correction actions.
System Scope
In the context of INTERSECT Systems, Subsystems, and Services, this pattern can be applied to INTERSECT systems and subsystems. It would be primarily applied to an entire infrastructure system and its subsystems, but it could also be applied an entire logical system that spans across multiple infrastructure systems. It could be applied to a logical subsystem of an infrastructure system only.
Service Scope
In the context of INTERSECT Systems, Subsystems, and Services, this pattern can be applied to an INTERSECT service. If it is applied to a group of services, then this is typically within the System Scope.
Microservice Scope
In the context of the INTERSECT Microservices Architecture, this pattern can be applied to an INTERSECT microservice. If it is applied to a group of microservices, then this is typically within the Service Scope.