Rejuvenation
The Rejuvenation structural pattern is a derivative of the Reconfiguration architectural pattern and the Fault Treatment and Fault Recovery strategy patterns in the original resilience design pattern specification (Fig. 32) [B24]. It offers detection, containment, and mitigation without restoring previously preserved state, employing redundancy, or self-masking or self-correcting illegal system state. The following describes the Pattern and its application in the System Scope and in the Service Scope of the INTERSECT federated ecosystem for instrument science. Note that the Pattern description uses the terms system, subsystem, and service in an abstract way, while the System Scope and the Service Scope map those terms to the INTERSECT federated ecosystem.
Pattern
- Problem
A hardware or software error or subsystem failure due to a physical fault (e.g., wear-out or destruction) or a design fault (e.g., resource underprovisioning) causes a software, such as a service, to experience an error or failure.
- Context
The pattern applies to a system that has the following characteristics:
The system is deterministic, i.e., forward progress of the system is defined in terms of the input state to the system and the execution steps completed since system initialization.
The system has well-defined parameters that enable a monitoring system to discover the presence of an existing or future fault, error, or failure in the behavior of the monitored system.
The interaction between the monitored and monitoring systems is bounded in terms of time.
The monitoring system has the capability to readily analyze the behavior of the monitored system to detect or predict a fault, error, or failure.
The experienced fault, error, or failure must not be persistent.
The system is capable of compartmentalizing its state that is accurately representative of the progress of the system since initialization at the time such state is captured.
The system operation has well-defined intervals that enable the pattern to transition the system to a known correct interval in response to an error or failure.
The system is capable of saving its current state and loading a previously saved state.
- Forces
The interactions between the monitoring and monitored systems may interfere with the operation of the monitored system, specifically its performance.
While the frequency and duration of these interactions must be minimized to reduce the monitoring overhead, the interactions must be able to detect or predict a fault, error, or failure in the monitored system.
The diagnostic resolution, i.e., the degree of accuracy of the fault diagnosis, must be high to be effective.
The ability of the system to rejuvenate subsystems or the entire system must permit system operation that is functionally equivalent to the fault-, error-, and failure-free operation.
The pattern requires additional persistent storage to capture system state, which increases overhead in terms of resources required by the system.
The creation frequency of system state snapshots determines overhead. More frequent snapshot creation increases system execution time, but reduces the amount of lost work upon an error or failure.
The time interval for the recovery of a system from a snapshot as well as the time interval to create a snapshot must be less than the system’s mean-time between failures (MTBF) to guarantee forward progress.
- Solution
The pattern alleviates the impact of a fault, error, or failure on system operation by restoring the affected subsystem or system to a known correct state. It has a detection component and an additional containment and mitigation component that acts upon the notification from the detection component.
The detection component enables the discovery of an existing or future fault, error, or failure in the system. It enables its containment and mitigation by notifying the system about it with location and type information. The solution requires a monitoring system, which may be a subsystem of the monitored system or an external independent system, to observe key parameters of the monitored system and to notify the monitored system when these parameters deviate. This pattern does not specify the detailed method of detection or prediction.
The containment and mitigation component acts upon the notification from the detection component by restoring the affected subsystem or system to a known correct state. The pattern relies on the creation of system state snapshots and the maintenance of such snapshots on a persistent storage system that is not affected by the fault, error, or failure. This pattern does not specify the detailed method of containment and mitigation.
Upon notification, the most recent snapshot is used to recreate the last known correct state of the affected subsystem or system. When the state is recovered, the operation of the system is resumed. Based on a temporal view of the system’s progress, the error/failure recovery may be either backward to the time when the snapshot occurred (rollback) or forward to the time when the event was detected or predicted (rollforward).
Undetected (latent) errors that are either detected later or result in a different detected error or failure later represent a problem, as the most recent or even more snapshots may contain an illegal system state. In this case, the most recent correct snapshot may be used to recreate the last known error/failure-free state of the system, skipping snapshots containing illegal state and going further back in time in terms of when the snapshot was made.
The pattern may create subsystems out of the system to temporarily isolate, but not permanently exclude, the affected subsystem. The interconnection between the subsystems is restored after subsystem or system rejuvenation. The components of this pattern are illustrated in Fig. 42.
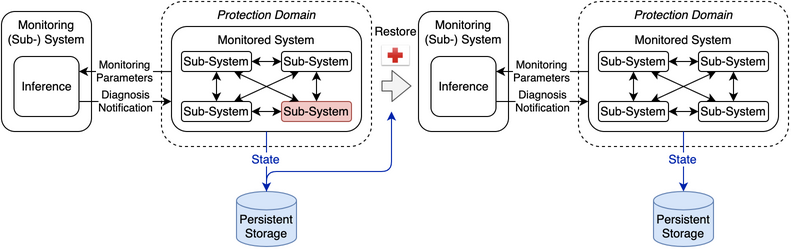
Fig. 42 Rejuvenation pattern components
- Capability
A system using this pattern is able to continue to operate in the presence of a non-permanent fault, error, or failure with some interruption and some or no loss of progress. This pattern provides detection/prediction, containment, and mitigation of a future or existing fault, error, or failure in the system by restoring the affected subsystem or system to a known correct state. The flowchart of the pattern is shown in Fig. 43, the state diagram in Fig. 44, and its parameters in Table 7.
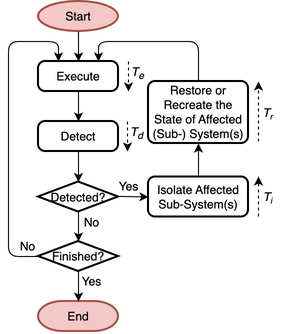
Fig. 43 Flowchart
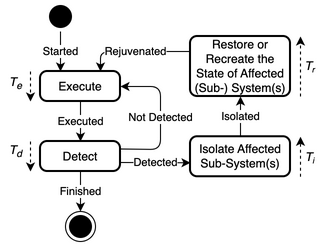
Fig. 44 State diagram
Table 7 Rejuvenation pattern parameters Parameter
Definition
\(T_{e}\)
Time to execute system progress
\(T_{d}\)
Time to detect or predict a fault, error or failure
\(T_{i}\)
Time to isolate the affected subsystem(s)
\(T_{r}\)
Time to restore or replace the state of the affected (sub-) system(s)
- Protection Domain
The protection domain extends to the monitored system’s state that is not lost due to a subsystem or system rejuvenation and to all of its resources that are able to be operate correctly after a rejuvenation.
- Resulting Context
A fault, error, or failure is prevented from affecting the correct operation of the system. While functional equivalency to the original system configuration is maintained through rejuvenation, progress in the system may be partially lost. The system is interrupted during rejuvenation in response to a detected or predicted fault, error, or failure. It is also interrupted during fault-, error-, and failure-free operation for preserving system state. After rejuvenation, the system’s ability to prevent a fault, error, or failure from affecting the correct operation of the system remains the same.
The pattern may be used in conjunction with other patterns that provide containment and mitigation in a complementary fashion, where some error/failure types are covered by the other pattern(s) and the pattern covers for the remaining error/failure types.
- Performance
In the case when the monitoring system is not a part of the monitored system, the monitoring system doesn’t impact the task’s total execution time \(T_{E}\). The error/failure-free performance \(T_{f=0}\) is \(T_{E}\).
When the monitoring system is a part of the monitored system, the failure-free performance \(T_{f=0}\) of the pattern is defined by the task’s total execution time without any resilience strategy \(T_{E}\) and the time to detect or predict a fault, error or failure \(T_{d}\) with the total number of input-execute-output cycles \(P\).
The performance under errors/failures \(T_{f!=0}\) is defined by \(T_{f=0}\), plus the time to isolate the affected subsystem(s) \(T_{i}\) and the time to restore or replace the affected subsystem(s) \(T_{r}\), for each of the encountered faults, errors or failures \(N\). Assuming constant times for \(T_{i}\) and \(T_{r}\), \(T_{f!=0}\) can be defined as:
\[\begin{aligned} T_{f!=0} = T_{f=0} + N (T_{i} + T_{r}) \end{aligned}\]- Reliability
Given that the pattern enables the resumption of correct operation after an error or failure, the reliability of a system employing it is defined by errors and failures that are not handled by the pattern, such as failures of the persistent storage. The reliability after applying the pattern \(R(t)\) can be obtained using the performance under failure \(T\) and the failure rate \(\lambda_{u}\) (or its inverse, the mean-time to interrupt (MTTI), \(M_{u}\)) of the unprotected part of the system.
\[\begin{aligned} R(t) = e^{-\lambda_{u} T} = e^{-T/M_{u}} \end{aligned}\]- Availability
The availability of the pattern can be calculated using the task’s total execution time without the pattern \(T_{E}\) and performance under errors/failures \(T_{f!=0}\). \(T_{E}\) is the planned uptime (PU) \(t_{pu}\). \(T_{f!=0}\) is the planned uptime (PU) \(t_{pu}\), the scheduled downtime (SD) \(t_{sd}\), and the unscheduled downtime (UD) \(t_{ud}\).
\[\begin{aligned} A = \frac{T_{E}}{T_{f!=0}} = \frac{t_{pu}}{t_{pu}+t_{ud}+t_{sd}} \end{aligned}\]
- Examples
The targeted rejuvenation of data structures in system software, such as operating system (OS) data structures, permits avoidance of and recovery from errors or failures without the need to reinitialize the affected compute node or the complete high-performance computing (HPC) system. The individual rejuvenation of HPC system services, such as the parallel file system metadata service (MDS) or the system’s resource manager, allows dealing with errors or failures without the need to reinitialize the entire HPC system.
- Rationale
The pattern prevents an existing or future fault, error, or failure from affecting the correct operation of the system through restoring the operation of the system or the affected subsystem. It relies on the capability to preserve system state before a detected or predicted fault, error, or failure, often in a periodic fashion, and restore the previously preserved system state upon detection or prediction of such an event to resume operation from a known correct state.
The pattern performs proactive actions, such as preserving system state, but mostly relies on reactive actions after notification about a detected or predicted fault, error, or failure. Progress in the system may be partially lost. Fault, error, or failure detection/prediction, containment, and mitigation are part of the pattern. The containment and mitigation offered by this pattern are independent from the type of fault, error, or failure. The pattern has very little to some design complexity and has low dependence on a system’s architecture.
System Scope
In the context of INTERSECT Systems, Subsystems, and Services, this pattern can be applied to INTERSECT systems and subsystems. It would be primarily applied to an entire infrastructure system and its subsystems, but it could also be applied an entire logical system that spans across multiple infrastructure systems. It could be applied to a logical subsystem of an infrastructure system only.
Service Scope
In the context of INTERSECT Systems, Subsystems, and Services, this pattern can be applied to an INTERSECT service. If it is applied to a group of services, then this is typically within the System Scope. However, it could also be applied to interconnected services, such as to services participating in the same campaign.
Microservice Scope
In the context of the INTERSECT Microservices Architecture, this pattern can be applied to an INTERSECT microservice. If it is applied to a group of microservices, then this is typically within the Service Scope.