Microservice Capabilities for Computation
Compute services broadly represent the ability to leverage local or remote computational resources to process data or run applications. For the INTERSECT Open Architecture, four types of computational resources are expected to be employed: (1) HPC systems, (2) cloud computing, (3) edge computing, and (4) individual host computers. HPC systems provide large-scale computational support for scientific modeling and simulation, high-throughput processing, and model training for AI using high-performance compute, storage, and networking hardware. Cloud computing provides general-purpose computational support using commodity server-based compute, storage, and networking hardware. A given cloud computing system may exist within an organization (i.e., a private cloud) or be publicly available on the Internet (i.e., a public cloud). Edge computing provides computational support for low-latency processsing of data produced by nearby sources (e.g., sensors or scientific instruments) using a variety of hardware (e.g., high-performance, commodity, or embedded). For host computing, the targeted host may exist within an HPC, cloud, or edge computing system.
There are two computing abstractions commonly provided by compute resources: batch computing or on-demand computing. Batch computing relies on resource management systems (e.g., LSF, PBS, and SLURM) to schedule, run, and monitor compute jobs across one or more job queues. Because batch computing systems are shared amongst many concurrent users with varied resource requirements and scheduling priorities, batch jobs have unpredictable completion latencies. Jobs may be queued for several hours or even days before being allocated resources to run. In contrast, on-demand computing provides instantaneous allocation when the requested resources are available, or the request will be immediately rejected. On-demand computing is currently not widely supported by HPC systems, but is readily available in cloud or edge computing environments.
Running Applications using On-Demand or Batch Computing Resources
A common scenario for use of computing resources is to deploy an application preconfigured for use in a particular computing environment. The application program and any dependent libraries are built for the target environment and packaged for use in a microservice providing the Application Execution capability (see Capability - Compute :: Application Execution). This microservice provides default settings for the application’s run configuration and program arguments. Since the Application Execution capability extends the Parameter Configuration capability (see Capability - Utility :: Parameter Configuration), the application microservice can also expose any configuration or parameter settings as client tunables.
The underlying mechanism to execute the application via an on-demand allocation or a job script is provided by another microservice that serves as the interface to the target environment’s compute resource manager. The compute resource manager microservice provides the Compute Allocation capability (see Capability - Compute :: Compute Allocation), the Compute Queue capability (see Capability - Compute :: Compute Queue), or both depending on the usage model of the environment.
Fig. 135 shows an example orchestration sequence for running such an application within an on-demand allocation of computing resources. Fig. 136 shows the sub-sequence relating to on-demand allocation of computing resources, while Fig. 137 shows the sub-sequence for running the application program within the allocation.

Fig. 135 Microservice interaction sequence for running an application within an on-demand allocation of computing resources.

Fig. 136 Microservice interaction sequence for allocating and releasing computing resources.

Fig. 137 Microservice interaction sequence for running and monitoring a program within allocated computing resources.
Fig. 138 shows an example orchestration sequence for running such an application using a batch computing job. Fig. 139 shows the sub-sequence capturing the batch job submission. Fig. 140 shows the sub-sequence to discover available batch computing queues.

Fig. 138 Microservice interaction sequence for running an application within a batch computing job.
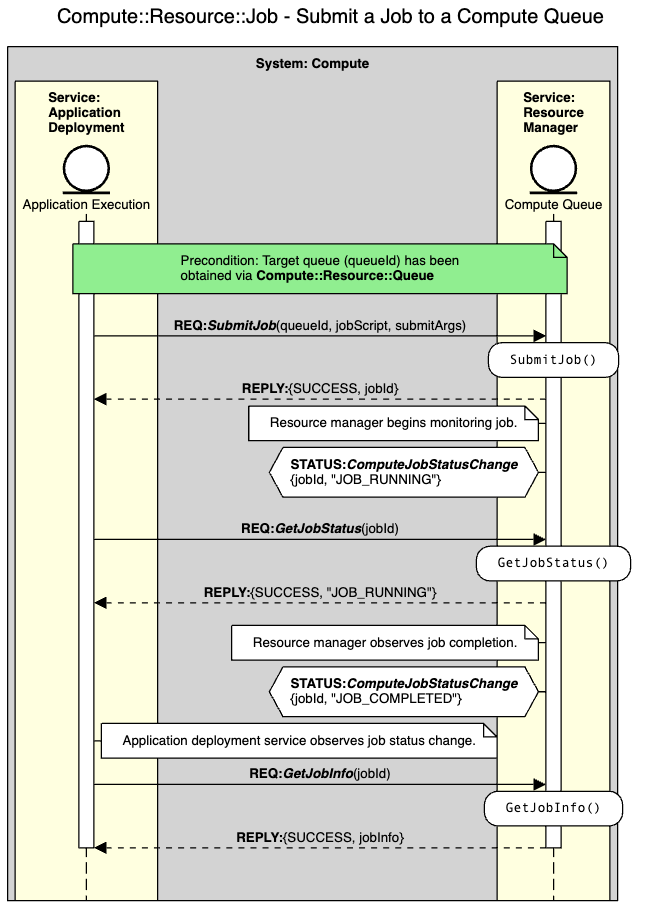
Fig. 139 Microservice interaction sequence for running and monitoring a batch compute job.

Fig. 140 Microservice interaction sequence for discovery of batch computing queues.